
变分自编码器
Abstract
本文根据知乎的二手资料(没读论文)调研了一遍市面上最主要的一些生成模型(没找 state-of-art 的微创新花活),并根据其发展脉络做了精简介绍,尽量罗列了其优劣、底层逻辑与实现。
在文章的第二部分,我们根据前面的综述详细分析了在 BECE 上应用 VAE 遇到的问题,不仅包括 VAE 本身的设计思路,还有 BECEC 的数据特征,都为 Encoder 的训练带来挑战。更麻烦的是,VAE 与 GAN 的应用都集中在图像处理方面,没找到我们能用的现成代码。
本文最后找出了 BECEC 训练问题的原因,并证明了所有的 AE 都不太可能有效。
生成模型:自编码器与生成对抗

生成模型分成了 VAE 与 GAN 两条路。从结果上看,二者互有优劣:VAE 生成的图像中规中矩,但是模糊;GAN 生成的图像清晰,但是喜欢乱来。原因:
- VAE 不容易找到合理判断生成图像好坏的标准,只能用 MSE 粗略计算误差
- GAN 的辨别器 D 没有充分训练时会导致生成器 G 钻空子,甚至可能学不好训练集
生成模型最常用以下四类网络:
- E:编码器 Encoder。给定一张图 x,可以将其编码为隐变量 z(且希望满足高斯分布)。如果还给定了类别 c,那么生成的隐变量就会质量更高(更随机)。
- G:生成器 Generator。给定隐变量 z(如随机噪声),就可以生成像模像样的图像。如果还给定了类别 c,那么就会生成像模像样的属于类别 c 的图像。
- C:分类器 Classifier。给定一张图 x,输出所属类别 c。
- D:辨别器 Discriminator。给定一张图 x,判断它是真实的图片,还是“电脑乱想出来的”。这是 GAN 首先引入的网络,它可以和 G 左右互搏,互相进步。
值得注意的是,GAN 没有编码器,而 AE 一般也只使用它的解码器。BECEC 希望将 BS 的 observation 进行压缩,因此无法从 GAN 方向做文章,而用 AE 也存在一些问题,我们会在下一节具体分析。
生成对抗网络 GAN
GAN 的本质是训练一个生成器 G与一个辨别器 D,二者分开训练。D 以最小化生成图像的分值,与最大化原始图像的分值为目标,来训练对生成图像的识别能力;G 以最大化辨别器的分值为目标,来训练制作更接近原始图像的生成图像。之所以叫做生成-对抗模型,是因为 D 希望能识别出“骗子”,而 G 希望能欺骗过 D,二者在训练中是一种对抗关系,最终达到 NASH 均衡。值得一提的是,G 的输入通常是高斯噪声。
现在常见的 GAN 模型更偏向 DCGAN,DC 也就是 Deep Convolutional。这种 GAN 网络将卷积神经网络的技术融入生成对抗中,去掉全连接层使之变成全卷积网络,并在层间插入 batch normalization 稳定训练过程。其中,生成器使用转置卷积层,可以理解成一种反卷积或上采样的过程。
GAN 的演进主要是在改写 D 的 Loss 函数。譬如 WGAN 就是基于 Wasserstein 距离设计了一种用神经网络计算分布间距离的方法,这种方法进一步简化成了对每 batch 生成图像的打分(不能只对单个图片打分、不再需要传入原始图像来计算距离)。WGAN-GP 则是引入了一个 gradient penalty,通过在 loss 函数中加入一个惩罚项让模型满足 Lipschitz 约束,避免 D 的 loss 掉到负无穷。
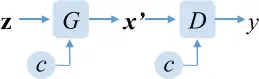
CGAN 则是将标签作为条件加入 GAN 之中,允许在生成图像时指定其类别(Conditional)。其实现也非常简单粗暴,直接在 G 与 D 网络的输入中增加关于条件 c 的维度。
自编码器 AE
AE 通过 Encoder 和 decoder 两个网络级联,将输入输出求差作 loss 进行训练,所得的 Encoder 能以尽量小的损失压缩输入数据。
DAE 希望 AE 能够对输入数据进行 denoising,它首先干净的输入信号加入噪声产生一个受损的信号,然后将受损信号送入传统的自动编码器中,使其重建回原来的无损信号。其目的是让模型更具鲁棒性,同时避免隐藏层训练出没有意义的恒等函数(类似 dropout?)。
VAE 从网络结构上看与 AE 差别不大,重点在于它的隐变量 z (编码结果)是从高斯分布中按一定的均值 与方差 采样出来的,这些均值与方差是编码器 E 生成的。对比 AE 的 E 网络输出的是 n 维 z 张量,VAE 的 E 网络则生成 2n 维张量,其中一半是 另一半是 。VAE 的名字中“变分”,是因为它的推导过程用到了 KL 散度及其性质。
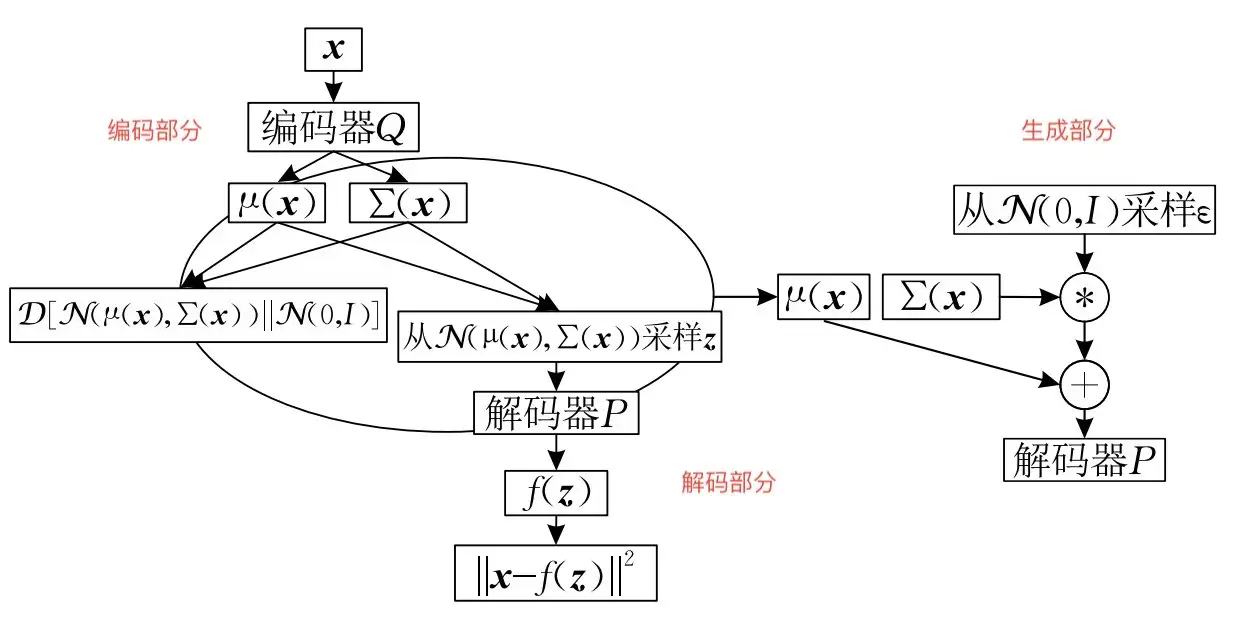
VAE 不仅需要保障生成图像与原始图像尽可能接近,还要让 E 的输出更接近标准正态分布 ,因此在 Loss 函数的设计中引入了一项与 间的 KL Loss,。具体可以看一下 Loss 代码的实践:
recons_loss =F.mse_loss(recons, input)
kld_loss = torch.mean(-0.5 * torch.sum(1 + log_var - mu ** 2 - log_var.exp(), dim = 1), dim = 0)
if self.loss_type == 'H': # https://openreview.net/forum?id=Sy2fzU9gl
loss = recons_loss + self.beta * kld_weight * kld_loss
elif self.loss_type == 'B': # https://arxiv.org/pdf/1804.03599.pdf
self.C_max = self.C_max.to(input.device)
C = torch.clamp(self.C_max/self.C_stop_iter * self.num_iter, 0, self.C_max.data[0])
loss = recons_loss + self.gamma * kld_weight* (kld_loss - C).abs()
VAE 同样也有带条件的 CVAE 变体。CAVE 的实现只需要修改 KL Loss,让 E 的输出保持单位方差,而均值 靠近每个类别专属的 ,。这里的 是用神经网络根据输入的 c 算出来的。
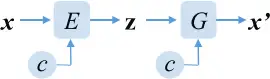
E+G+C+D = CVAE-GAN
CVAE-GAN 是 CGAN 与 CVAE 的取长补短:
- VAE 有原始输入 x 指导 G 的训练,能至少保证 G 对训练集的学习效果,因此前半部分是 AE 的结构
- GAN 的 D 能用更好的标准来评价 G,所以最终还是通过 D 输出的评价 y 来训练 G
- 同时我们还得真的保证生成的图像是属于 c 类别,于是引入 C 参与对 G 的评价

G 的 Loss 有三大部分组成:
- :对于从 x 生成的 z,G 应该更还原出接近 x 的 x’ (像素上的接近)
- :G 生成的图像应该可以由 C 鉴别为属于 c
- :G 生成的图像应该可以由 D 鉴别为属于真实图像
VAE 用在 BECEC 的问题
BECEC 遇到的问题是 State 维度太大,单靠 RL 的全连接层很难有效提取环境信息,训练总收敛到一些不算太好的局部最优点。因此,我们希望找到一种合适的编码方案,压缩 observation 的同时让 RL 能够有效训练。这里就有两个注意点:
- 编码:需要能够编码,因此不能用 GAN
- 有效:RL 要求相近的环境也有类似的 State,否则不能泛化,因此 md5 等压缩手段果断不行
VAE 的本质
首先,我们需要明确 AE 的本质是从输入 x 中提取出隐变量 z,然后根据 z 还原出 x’。这里我们强调的是“提取”和“还原”,因为一些 AE 的实践中,Encoder 的输出维度甚至比原输入 x 的维度还大,AE 用于压缩的效果并不一定好,高度依赖数据特征。
AE 所做的是压缩与还原,我们只希望它能按某个标准进行数据压缩,因此它所做的很大程度是无用功,这也是 ML-DDPG 所批判的。然而 ML-DDPG 本身的实现非常拙劣,另一篇报告中也分析了它应用在 BECEC 中会有多么严重的问题。简而言之就是需要花费我们训练 RL 差不多的时间去训练它,并且在知道 critic 没法喂饱的前提下,使用 critic 网络差不多结构与训练方式的 ML-DDPG 也一样会遇到 critic 碰到的问题。
在 BECEC 中,我们真正希望得到的是每个 BS 在将来 delta_t 个 slots 上的资源分布与余量特征,不需要啥信息都提取出来。在用最简单 AE 的实践中,我们发现 30 个 slots 的信息甚至很难压缩成 15 维的隐变量 z,而用满 10 个 slots 的 observation 就已经非常难训练了,我们还是尽可能希望单个 BS 的特征在 5 维以内。
于是,我们开始调研 VAE 及其后续的一些发展模式。如上一章所总结的,VAE 希望将输入 x 压缩成一系列高斯噪声组成的张量,这是为了方便它本来的工作:根据随机出的张量 z 生成大量类似训练集的数据来扩充数据集。 也就是说,现在 VAE 的发展方向主要是研究怎么能有个牛逼的生成器 G,而不是让编码器 E 的效果有多好。同时,VAE 并不需要让 E 尽可能减小 z 的维度,因为其目的不在压缩,而是得到一种从噪声中生成目标数据的方法。在我看到的 VAE 代码中,z 的维度都设计的很大,否则很难保证 G 的生成能力,并且高维度的 z 也不怎么影响人们去使用 G,毕竟只是多生成一些随机数罢了。从 VAE 的设计思路与其应用场景来看,我对 VAE 能够胜任 BECEC 的希望渺茫。
同时,VAE 与 AE 也没有本质区别,除了大部分场景下 VAE 都是处理图像问题,其网络结构都是全卷积的形式。对于 BECEC 这种没法卷积的 observation,如果自己实现全连接层的 VAE,则除了它的 E 生成的是 n 组 外,和普通的 AE 一摸一样。这样看,除了引入了不确定性以增加 G 的鲁棒性外,VAE 对于 E 的训练并没有什么帮助。BECEC 无论用 AE 还是用 VAE,基于上述理论分析都是差不多的。
Observation 的输入分布
前面我们讲了 AE 的弊端,以及 BECEC 难以使用 AE 的实验结果,现在我们仔细分析一下为什么会出现这种情况。
首先需要明确的是神经网络的输入。BECEC 的 Observation 由 M 个基站状态与 n_tasks 个任务状态组成,其中每个任务只有 、、 三个状态,而基站有 delta_t 个 slots 的状态。造成 Observation 维度过大的罪魁祸首就是基站信息,因此我们希望对其进行压缩。我们的方案是,训练一套统一的 Encoder,输入的是 delta_t 个 slots 的数据,输出一个不大于 5 的特征信息,作为 Observation 中某个基站的状态。

那么,我们需要分析的就是每个基站在 delta_t 个 slots 中的剩余 CPU 资源状况。值得一提的是,在 BECEC 的论文中,我们设计的 state 是包含了每个 slot 上的资源单价的,但因为单价是直接从 CPU 余量中计算来的,在实践中二者是重复信息,只需要保留剩余资源量即可。让我们观察一下新 slot 中资源更新的过程:
- 随机生成 [0.5, 1.25] 间的随机数,表示新 slot 中需要处理的任务占总资源量的多少
- 将大于 100% 的部分变成外包任务让资源占用量不到 80% 的基站帮忙
可以发现,新旧 slot 间的资源占用量是没有联系的,AE 拿到的训练数据基本上就是 delta_t 个 [0.5, 1] * Capacity 的随机值,而每个基站的 Capactiy 也是固定的,因此 AE 进行压缩的对象就是一段从均匀分布采样出的样本!只不过有 1/3 的比例值为 Capacity。就算有外来任务被分配过来了,也依然不太能影响这些 slots 的特征,不过是让值为 Capacity 的比例更高罢了。
让我们来分析一下这种数据的熵值。首先,其中有 1/3 以上的比例恒定为 Capacity,这部分的熵为 0,剩下的 2/3 则来自均匀分布,因此其熵可以看成均匀分布熵值的 2/3。这也难怪 AE 无法有效压缩这些数据,因为这段数据不过是带 1/3 固定值的噪声!考虑到 VAE 的原理,是将输入数据转变成一批高斯噪声组成的张量,然后再从这些噪声张量中还原出原始数据。在 BECEC 这里,就成了把一批近似均匀分布的噪声压缩成高斯分布的噪声,这明显不可行。就算将全连接层换成了 NLP,我都不觉得 VAE 能训练出结果。
而在做这部分分析的时候,我突然想明白了为什么 BECEC 的 RL 学不好了,问题一样是这里说的熵值过大问题!仔细一想,我们的 Observation 中的大部分不就是 M*delta_t 个随机数吗,两个 States 间的状态更新也过于随缘,Critic 学的就是状态的变化(TD-error),如果 States 变化的连贯性过低,很容易想象 Critic 不可能学好。而 Actor 就不存在这个问题,它只用关心当前环境状态的影响,因此我们能看见 Actor 的 Loss 曲线是正常的,而 Critic 则非常不稳定。或许让 Critic 只关注眼前利益更好?
我们还有一个证据,能够进一步证明环境更新过于随机导致了 Critic 拟合失败。在我们九月份的实验中,将基站的数量以及 delta_t 的长度都进行了大幅度调低,只有这种情况下 RL 才正面打过了启发式算法(虽然在都使用辅助轮的情况下启发式更胜一筹)。而十月我们将 delta_t 调回了 30,基站数量未变,RL 的性能则一泻千里,和随机策略差不多。这是因为 delta_t 较小时大量 slots 会被分配占满,这时候俩状态更新之间的关联性是非常强的。比如说,当 Actor 给 BS0 分配了任务,那么该 BS 的状态就可能变得几乎全是 Capicity;而当 Actor 分配给了一个错误的 BS3(满负荷),该 BS 会直接丢弃任务。这种环境下,Action 对状态更新的影响非常大,因此 Critic 能在一定程度上学好。而当 delta_t 变得很大时,交付一个任务的影响就是在几百个随机值中选了几个变成 Capacity,相邻状态更新之间依旧像是与 Action 毫不相干的。
写到这里,我突然意识到另一个问题。系统是等到每次集齐 n_tasks 个任务时才会执行一次调度,而这时才会进行一次 Observation 的采样。也就是说,相邻 States 间的关联性可大可小。当系统中很长一段时间都没有集齐任务时,两个 States 间就可能差了不止 delta_t 个 slots,这时它们是毫无关联的!这种 Observation 的采集方式本身也对 Critic 的训练提出了不小挑战。
现在 Critic 验明的问题:
- Ciritc 网络欠拟合
- 环境过于随机,就不可能学出状态更新
- 每个状态是在集齐 n_tasks 个任务时采集的,两个状态之间本身就可能毫无关联